MiniCache: KV Cache Compression in Depth Dimension for Large Language Models
A critical approach for efficiently deploying computationally demanding large language models (LLMs) is Key-Value (KV) caching. The KV cache stores key-value states of previously generated tokens, significantly reducing the need for repetitive computations and thereby lowering latency in autoregressive generation. However, the size of the KV cache grows linearly with sequence length, posing challenges for applications requiring long context input and extensive sequence generation. In this paper, we present a simple yet effective approach, called MiniCache, to compress the KV cache across layers from a novel depth perspective, significantly reducing the memory footprint for LLM inference. Our approach is based on the observation that KV cache states exhibit high similarity between the adjacent layers in the middle-to-deep portion of LLMs. To facilitate merging, we propose disentangling the states into the magnitude and direction components, interpolating the directions of the state vectors while preserving their lengths unchanged. Furthermore, we introduce a token retention strategy to keep highly distinct state pairs unmerged, thus preserving the information with minimal additional storage overhead. Our MiniCache is training-free and general, complementing existing KV cache compression strategies, such as quantization and sparsity. We conduct a comprehensive evaluation of MiniCache utilizing various models including LLaMA-2, LLaMA-3, Phi-3, Mistral, and Mixtral across multiple benchmarks, demonstrating its exceptional performance in achieving superior compression ratios and high throughput. On the ShareGPT dataset, LLaMA-2-7B with 4-bit MiniCache achieves a remarkable compression ratio of up to 5.02x, enhances inference throughput by approximately 5x, and reduces the memory footprint by 41% compared to the FP16 full cache baseline, all while maintaining near-lossless performance.
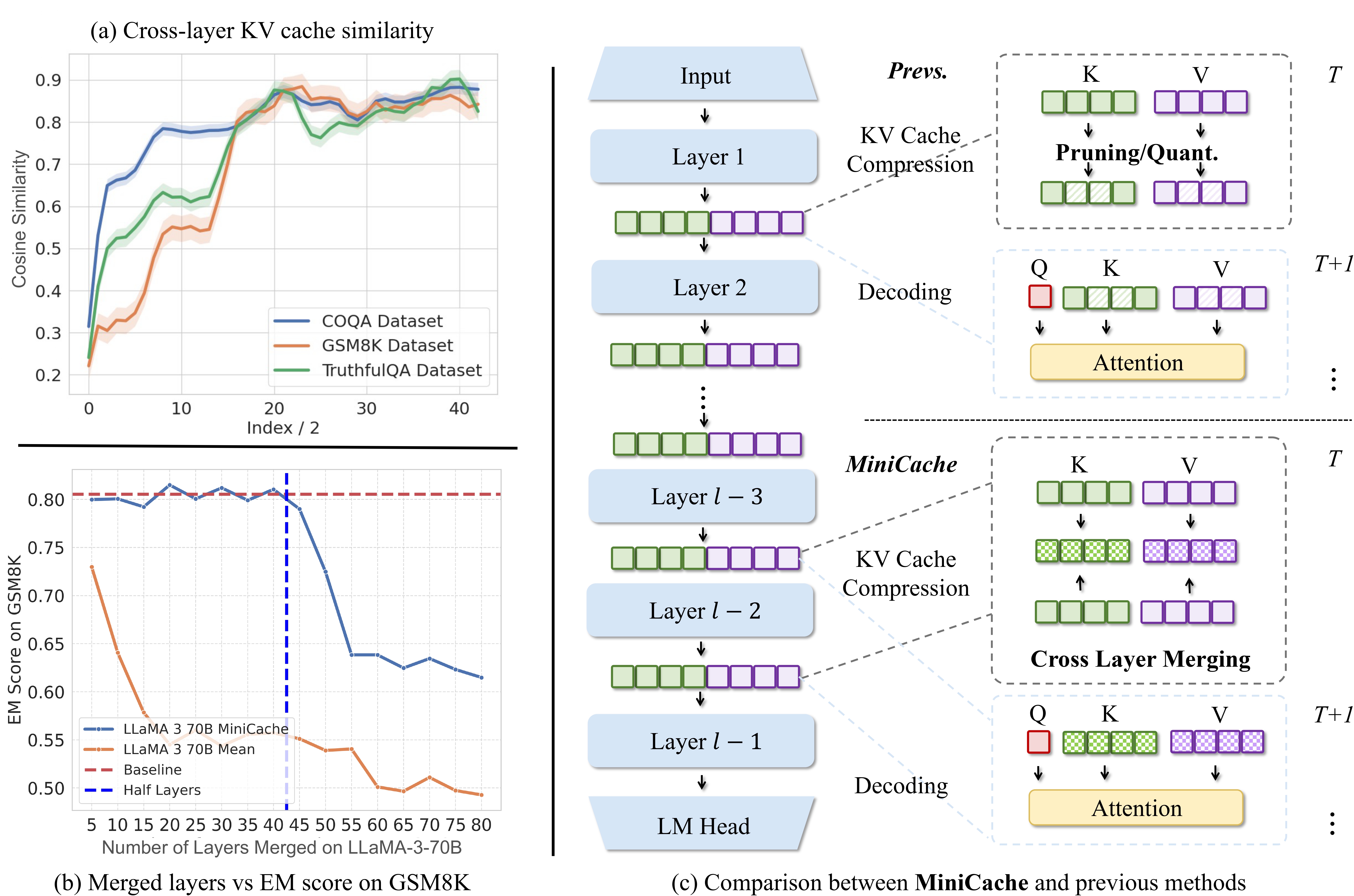
Overview of our MiniCache strategy and example results: (a) shows the observation that the KV cache states between two adjacent layers are highly similar, particularly across the middle to deep layers. The x-axis uses index/2 to represent the similarities for each pair of layers. (b) compares the performance of MiniCache, and the mean baseline, which simply averages the KV caches of two layers, using the LLaMA-3-70B model on the GSM8K dataset. MiniCache, which begins merging from the half-layer depth, achieves near-lossless performance. (c) highlights the primary difference between MiniCache and previous approaches. MiniCache investigates the inter-layer redundancy of KV caches along the depth dimension of LLMs, an aspect overlooked by intra-layer-based methods. Here, T refers to the last timestamp of pre-filling, and T+1 des to the first timestamp of decoding.
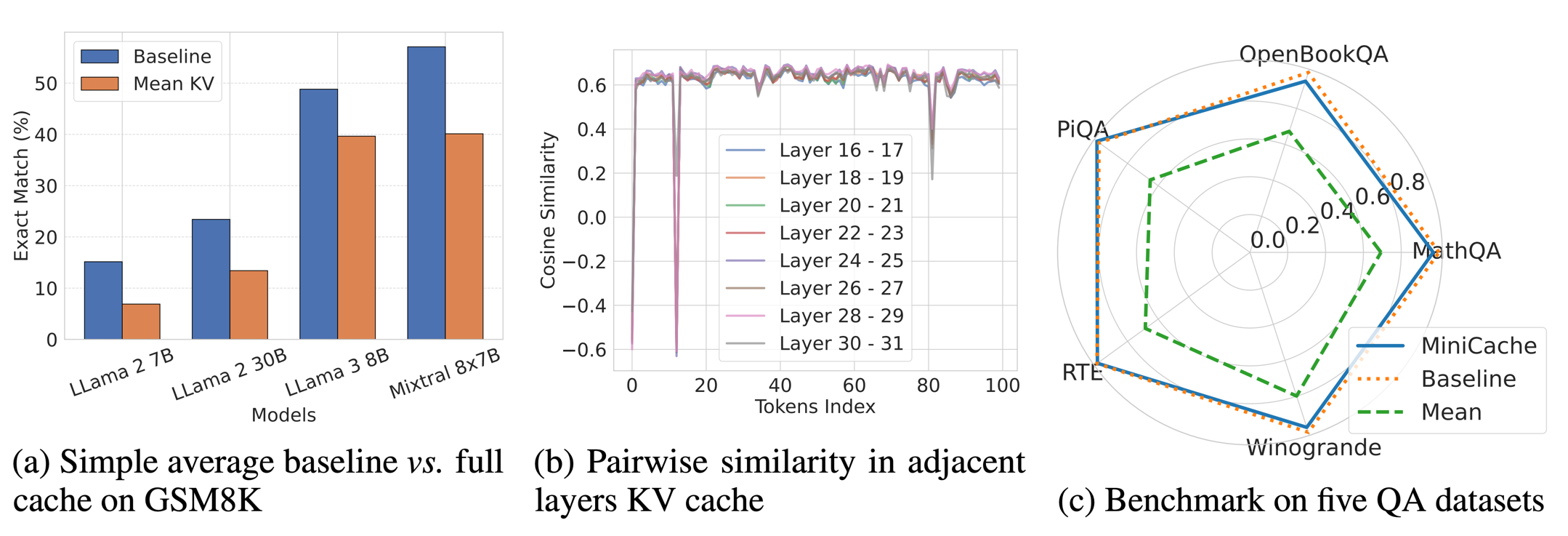
Overall of our explorations and observations : (a) shows the strong baseline by performing average merging on the KV cache. (b) shows the pairwise similarity of cache states between adjacent layers. (c) compares the MiniCache, simple average, and full cache baseline across five different datasets.
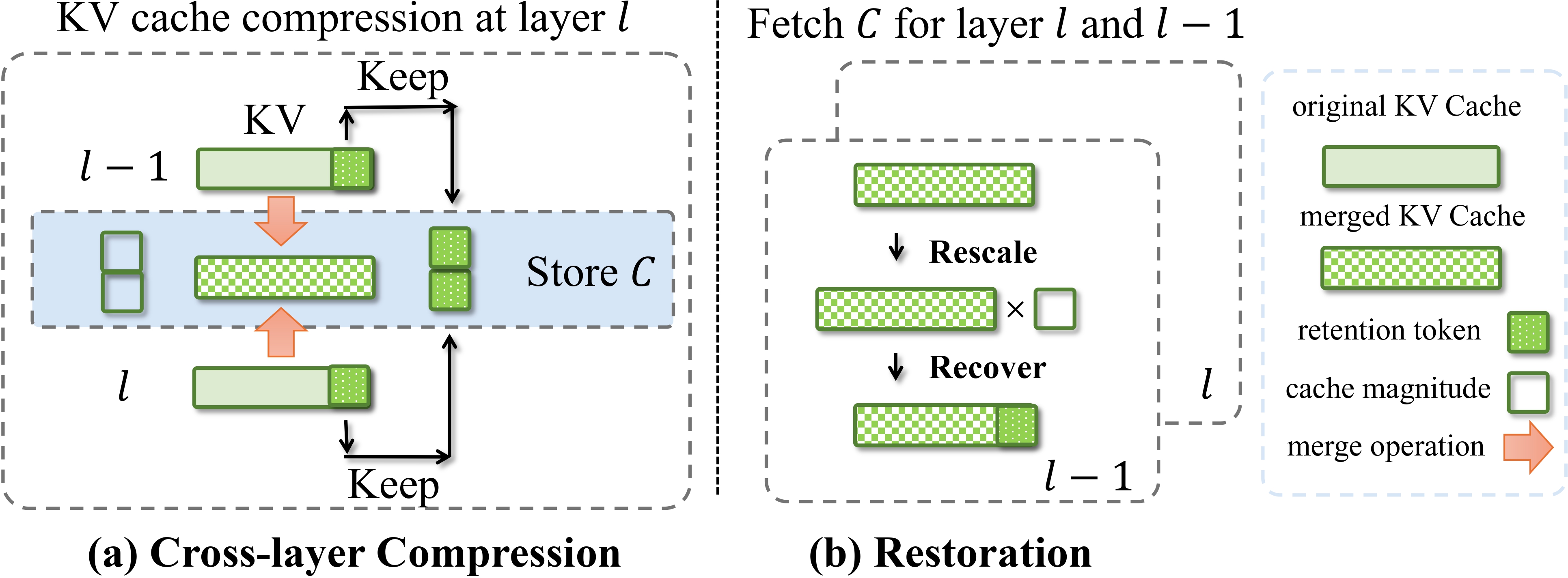
The illustration of the proposed method MiniCache. (a) depicts the cross-layer compression process. We fetch the KV caches, from layers l and l-1, and merge them into shared states via Eq.~(3). Additionally, we compute the ℒ2 norm for the caches to obtain their magnitudes. Furthermore, we select unmergable tokens for retention, then store merged cache, retention tokens, and magnitudes at layer l in C. (b) illustrates the restoration process for layers l and l-1, which includes magnitude rescaling in Eq.~(2) and retention token recovery.
Performance comparisons between our proposed MiniCache with the “averaging baseline” and the “unmerged full cache baseline” on multiple datasets with Phi3-Mini, Mixtral-8x7B, LLaMA-3-8B, and LLaMA-3-70B. More result details are shown in Section 4. The x-axis indicates the number of layers merged. As more layers are merged, a greater reduction in memory usage is achieved.
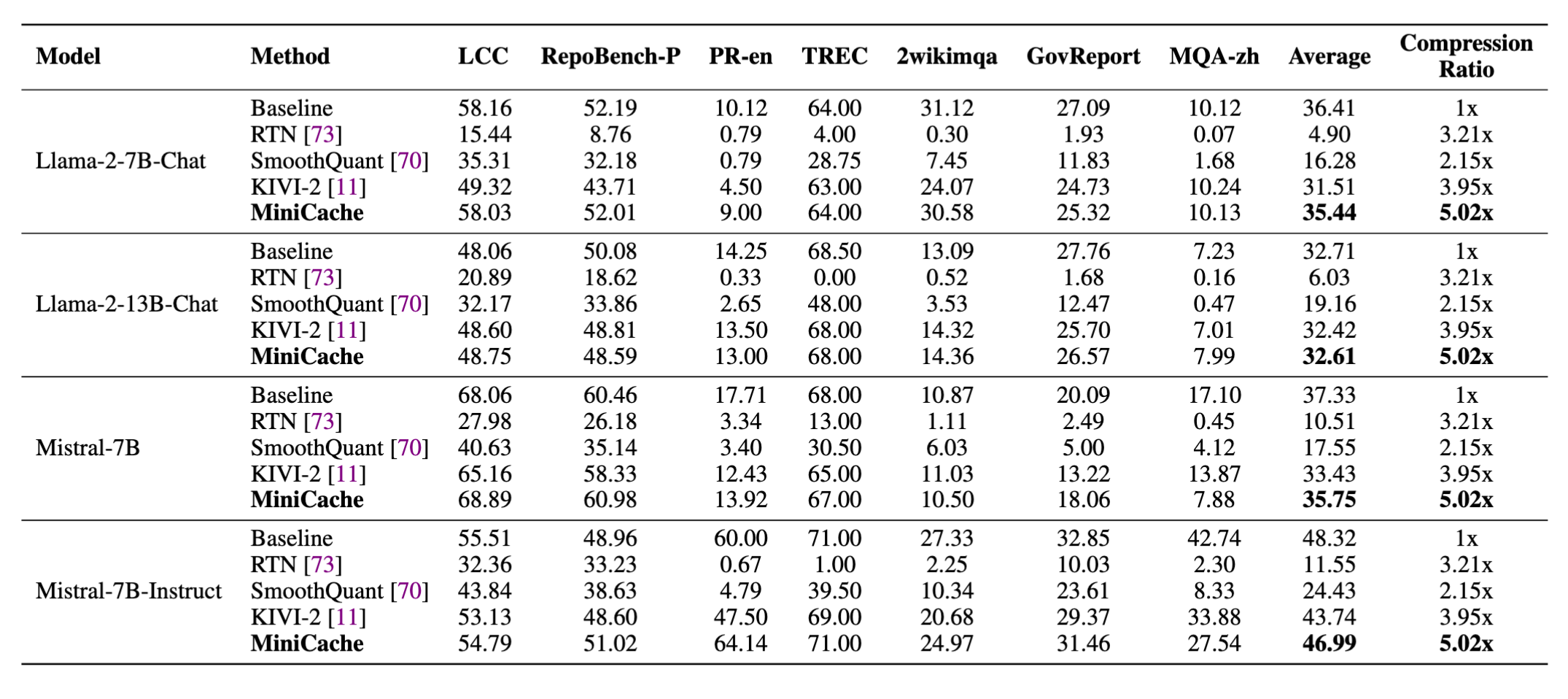
Evaluation of different KV cache compression methods on LongBench. MiniCache builds on top of 4-bit KIVI and achieves the best performance with the strongest compression rate.
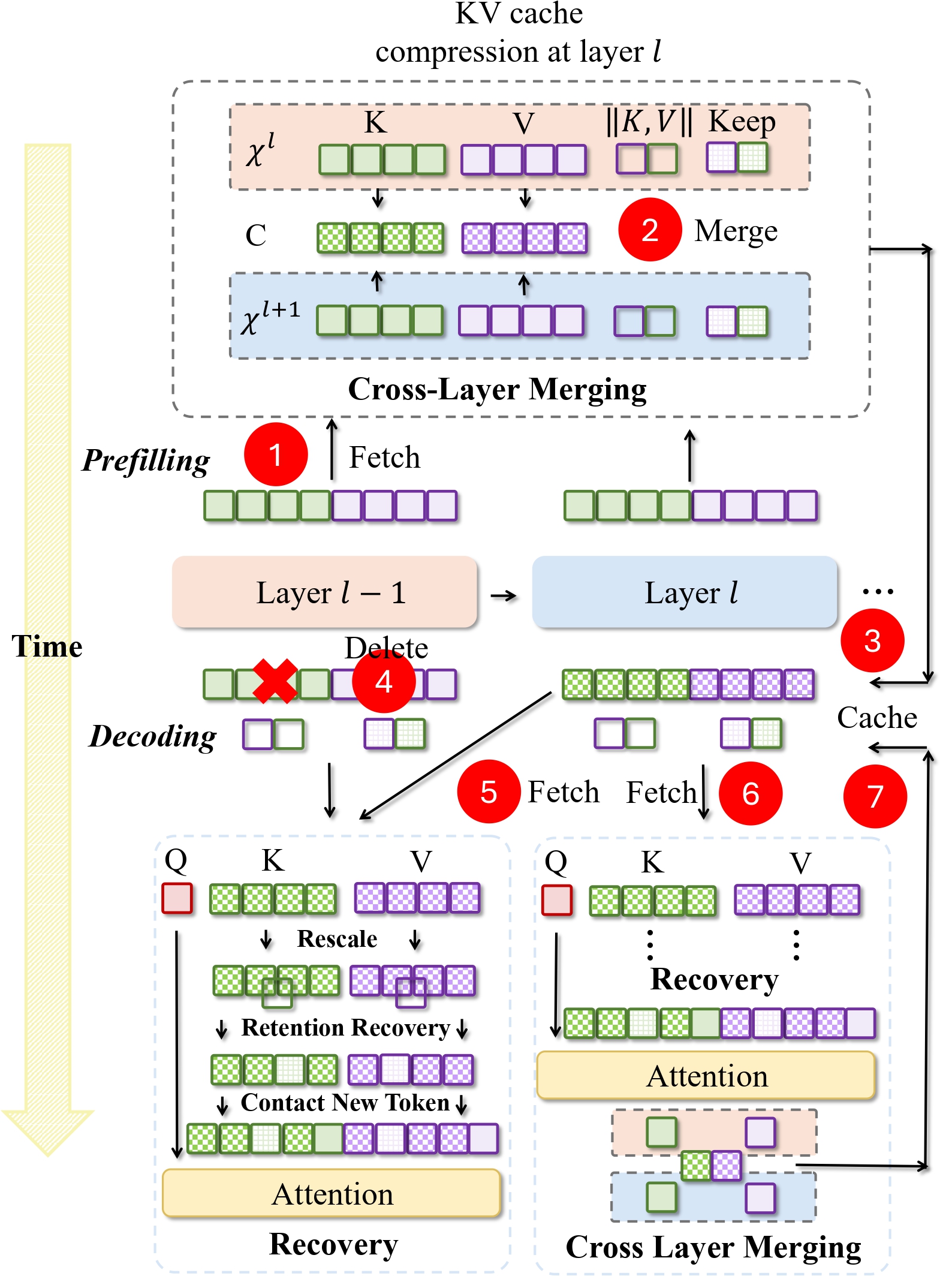
Overall prefilling and decoding logic for MiniCache involves performing cross-layer merging and recovery within our framework.
@article{liu2024minicache,
title={MiniCache: KV Cache Compression in Depth Dimension for Large Language Models},
author={Liu, Akide and Liu, Jing and Pan, Zizheng and He, Yefei and Haffari, Gholamreza and Zhuang, Bohan},
journal={arXiv preprint arXiv:2405.14366},
year={2024}
}
